클러스터링은 사용되는 분야와 데이터 특징에 따라 정말 다양하게 응용되고 있습니다. 하지만, 기본적인 '군집'의 메커니즘은 모두 동일하기 때문에 논문에서 아이디어를 제안하면서 사용되는 데이터는 그림 1과 같이 2차원 데이터입니다. 이번 포스팅에서는 Application 단계 이전에 클러스터링 연습이나 구현 또는 제안하려는 기법의 평가를 위해 사용되는 2차원 데이터 몇 가지를 소개하겠습니다.

1. 데이터 다운로드
git clone https://github.com/DEEPI-LAB/clustering-dataset.git
데이터가 많다보니 정리가 어려워 깃허브에 올렸습니다. 링크를 통해서도 받으실 수 있습니다.
github.com/DEEPI-LAB/clustering-dataset
DEEPI-LAB/clustering-dataset
2d spatial dataset for clustering evaluation. Contribute to DEEPI-LAB/clustering-dataset development by creating an account on GitHub.
github.com
2. 데이터 확인
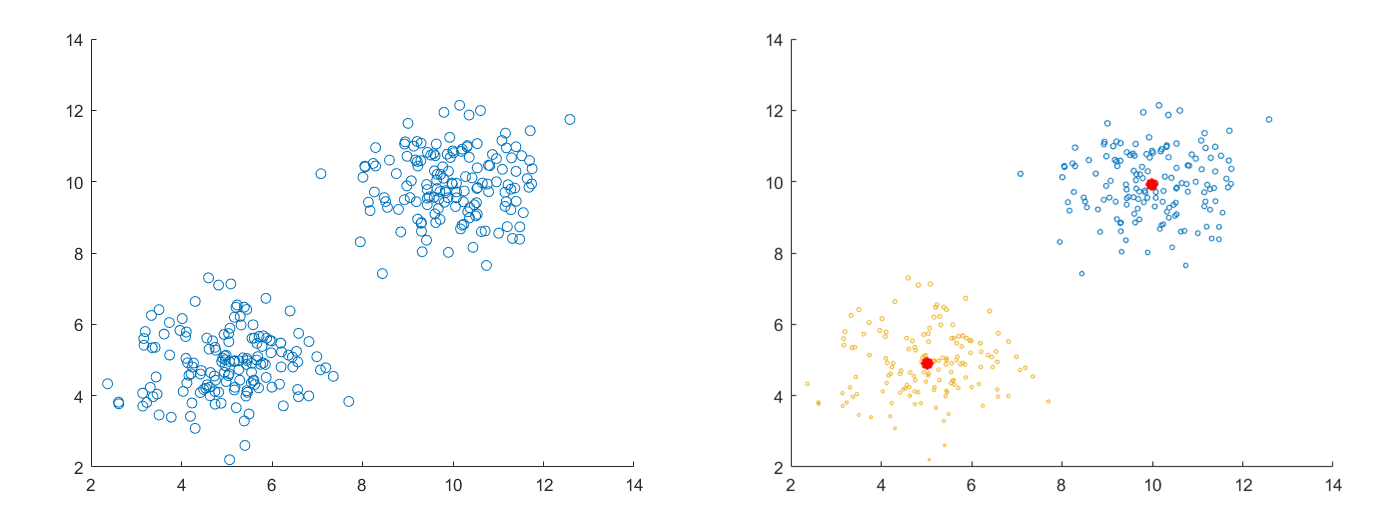

2개의 군집을 가지는 0번 데이터는 K-Means로도 쉽게 군집됩니다. 하지만 군집 모양과 크기가 다른 1번 데이터 군집은 실패하였습니다. 구현을 위한 k-Means 알고리즘은 이전 포스팅을 참고하시면 됩니다.
[Matlab] K-Means Clustering (K-평균 군집화) 알고리즘 구현하기
1967년 처음 제안된 K-Means 클러스터링 (K-평균 군집화)은 군집화 알고리즘의 시작을 알린 데이터 마이닝 기법입니다. 파티션을 분리하는 기법 (Partitioning) 으로 분류되는 K-means 는 사전에 부여된 클
deep-eye.tistory.com


2번 데이터는 0번과 비교하여 동일하지만, 겹침 문제 (joint problem)이 일부 존재합니다. 3번 데이터는 학습 초기값에 따라 실패할 수도 있는 데이터입니다.


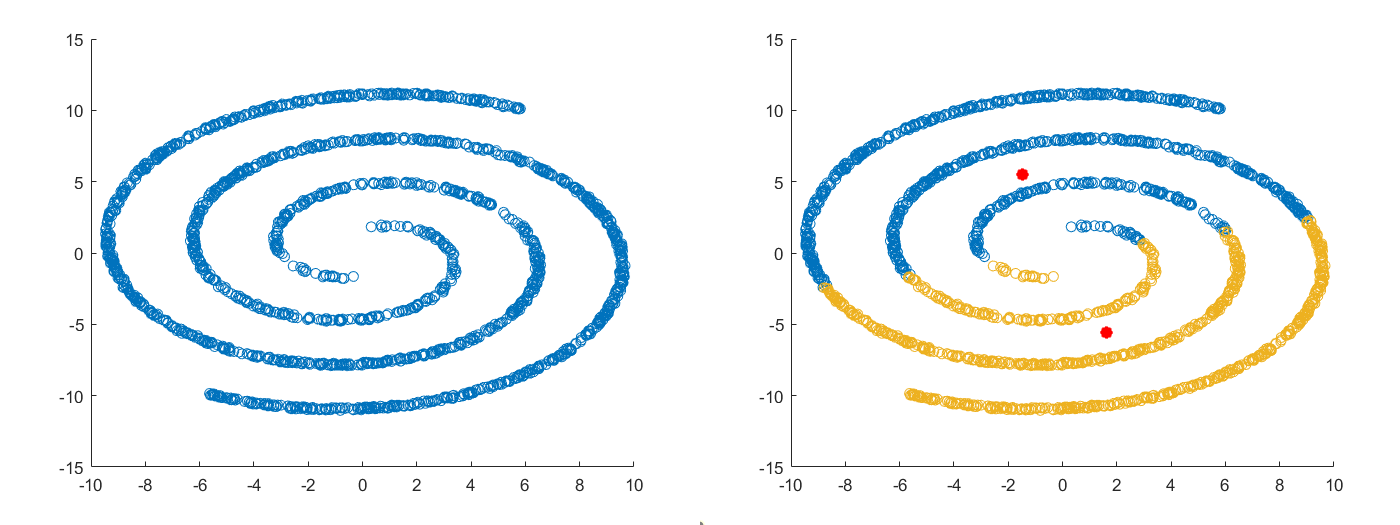
갑자기 군집 난이도가 상승했습니다. 4-6번 데이터는 클러스터의 밀도가 서로 다르거나, 잡음이 추가되었습니다. 또한, 원형이나 사각형 형태의 군집이 아닌 비선형성을 가지는 데이터 집합입니다. 이외에 7 - 9번 데이터는 라벨 정보도 포함된 데이터이며 실제 성능평가로도 활용되고 있습니다. 논문에서 클러스터링 알고리즘을 새롭게 제안한다면 한 번 시도해보시길 바랍니다.
# Jetson 시리즈 응용 임베디드 머신러닝 시스템 제작
# 머신러닝 프로젝트 제작, 상담 및 컨설팅 / 머신러닝 접목 졸업작품 컨설팅
# 데이터 가공, 수집, 라벨링 작업 / C, 파이썬 프로그램 제작
# email : deepi.contact.us@gmail.com
# site : www.deep-i.net
'Matlab' 카테고리의 다른 글
| [Matlab] 다층 퍼셉트론(MLP)을 이용한 MNIST 손글씨 인식 알고리즘 구현 (0) | 2020.12.05 |
|---|---|
| [Matlab] 매트랩에서 GIF 이미지(애니메이션) 파일 만들기 (1) | 2020.11.29 |
| [Matlab] K-Means Clustering (K-평균 군집화) 알고리즘 구현하기 (0) | 2020.11.24 |
| [Matlab] 매트랩을 이용한 다층신경망 (Multi-Layer Perceptron: MLP) 구현하기 (XOR 문제) (0) | 2020.11.01 |
| [Matlab] 객체 탐지 알고리즘 학습을 위한 이미지 데이터 라벨링 #2 (0) | 2020.07.31 |