Concept
DBSCAN (Density-based Spatial Clustering of Applications with Noise)은 비선형 클러스터의 군집이나 다양한 크기를 갖는 공간 데이터를 보다 효과적으로 군집하기 위해 이웃한 개체와의 밀도를 계산하여 군집하는 기법입니다.
K-Means와 같이 군집 이전에 클러스터의 개수가 필요하지 않고 잡음에 대한 강인성이 높기 때문에 현재까지도 다양한 분야에서 활용되고 있습니다. 이번 포스팅에서는 파이썬을 이용해서 DBSCAN 알고리즘을 구현해보도록 하겠습니다.

Algorithm
사실 DBSCAN은 컴퓨팅 알고리즘으로 제안된 기법이기 때문에 특별한 수식이 존재하지 않습니다. 2가지 파라미터만 기억하면 됩니다. 이웃과의 거리를 나타내는 최소 이웃 반경 ϵ 과 최소 이웃 수 minPts입니다.
- 1. 각각의 객체들은 반경 ϵ 을 기준으로 최소 이웃 minPts 이상을 충족하면 군집
- 2. 최소 이웃 minPts를 충족하지 못하면 잡음으로 판단
- 3. 군집되었다면 군집된 이웃 객체를 대상으로 1번 반복
K-Means처럼 전체 데이터의 분포 특성을 통해 중심점을 추정하는 방식이 아닌, 개별적인 객체 하나하나의 밀도 특성을 1-3번 알고리즘을 반복하며 군집하게 됩니다. 모든 객체는 한 번 연산된 이후에는 다시 군집되는 일이 업도록 Flag를 지정해줍니다. 처음 시작하는 객체는 초기화를 통해 무작위로 뽑히게 되며 군집이 완료되면 그림 2와 같이 군집에 속하는 Core와 Border, 그리고 Outlier로 판단되는 Noise 값으로 분류할 수 있습니다.
- Core Vector(object) : 임의의 벡터로부터 반경 ϵ내에 있는 이웃 벡터의 수가 minPts보다 클 경우, 하나의 군집을 생성하며 중심이 되는 벡터
- Border Vector(object) : 핵심 벡터로부터 거리 ϵ내에 위치해서 같은 군집으로 분류되나, 그 자체로는 핵심 벡터가 아닌, 군집의 외각에 위치하는 벡터
- Noise Vector(object) : 핵심 또는 외각 벡터가 아닌, 즉 ϵ 이내에 mitPts개 미만의 백터가 있으며, 그 벡터들 모두 핵심 백터가 아닐 경우, 어떠한 군집에도 속하지 않는 벡터
Complexity
클러스터링 분야에서는 빅데이터를 다루는 만큼 연산 복잡성이나 메모리 등을 고려해야 합니다. 일반적인 DBSCAN은 각 객체와 객체 사이의 모든 거리가 필요합니다. 군집 과정에서도 하나하나 군집되기 때문에 시간 연산 복잡성은 보통 전체 데이터가 N개 일 때, O(Nlog(N)) O(N2) 정도입니다. 그래프 기반 클러스터링 O(N3) 보다는 매우 낮지만 데이터가 방대해지면 무시 못할 수준인 것 같습니다.
Python Code
사용된 라이브러리는 Numpy, Scipy 그리고 Plot 표현을 위한 Matplotlib입니다. 기초적인 수준에서 활용하였기에 버전 이슈는 크게 없을 것 같습니다. git 또는 링크를 통해 압축 파일 형태로 받아주세요.
필수 라이브러리
pip install numpy scipy matplotlib소스 코드 다운로드
git clone https://github.com/DEEPI-LAB/dbscan-python.gitgithub.com/DEEPI-LAB/dbscan-python
DEEPI-LAB/dbscan-python
Contribute to DEEPI-LAB/dbscan-python development by creating an account on GitHub.
github.com
0. DBSCAN 파라미터 초기화
def __init__(self,x,epsilon,minpts):
# The number of input dataset
self.n = len(x)
# Euclidean distance
p, q = np.meshgrid(np.arange(self.n), np.arange(self.n))
self.dist = np.sqrt(np.sum(((x[p] - x[q])**2),2))
# label as visited points and noise
self.visited = np.full((self.n), False)
self.noise = np.full((self.n),False)
# DBSCAN Parameters
self.epsilon = epsilon
self.minpts = minpts
# Cluseter
self.idx = np.full((self.n),0)
self.C = 0
self.input = x
입력 X, 최소 이웃 반경 epsilon, 최소 이웃 개수 minpts를 입력으로 하는 DBSCAN 클래스로 코드를 구현했습니다. 군집 이전 모든 객체의 초기 인덱스(self.index)는 0으로 초기화했으며, 방문 flag(self.visited)와 잡음 인덱스(self.noise)를 통해 한 번 연산된 객체와 잡음 객체는 다시 연산되지 않도록 하였습니다.
1. DBSCAN 군집 단계 #1
def run(self):
# Clustering
for i,vector in enumerate(x):
if self.visited[i] == False:
self.visited[i] = True
self.neighbors = self.regionQuery(i)
if len(self.neighbors) > self.minpts:
self.C += 1
self.expandCluster(i)
else : self.noise[i] = True
return self.idx,self.noise
# 최소 반경 이내 최소 이웃 수를 만족하는 군집 찾기
def regionQuery(self, i):
g = self.dist[i,:] < self.epsilon
Neighbors = np.where(g == True)[0].tolist()
return Neighbors
입력 데이터를 스캔하며 방문 flag를 체크합니다. False일 경우, RegionQuery 함수로 군집 밀도를 충족하는지 판단합니다. 군집 요건을 만족하게 되면 군집된 이웃 객체를 대상으로 RegionQuery를 다시 반복하기 위해 ExpandCluster 함수를 실행해줍니다.
2. DBSCAN 군집 단계 #2
def expandCluster(self, i):
self.idx[i] = self.C
k = 0
while True:
try:
j = self.neighbors[k]
except:pass
if self.visited[j] != True:
self.visited[j] = True
self.neighbors2 = self.regionQuery(j)
if len(self.neighbors2) > self.minpts:
self.neighbors = self.neighbors+self.neighbors2
if self.idx[j] == 0 : self.idx[j] = self.C
k += 1
if len(self.neighbors) < k:
return
3. 최종 코드
# -*- coding: utf-8 -*-
"""
Project Code: DBSCAN v1.0
@author: Deep.I Inc. @Jongwon Kim
Revision date: 2020-12-07
Contact Info: :
https://deep-eye.tistory.com
https://deep-i.net
"""
import numpy as np
from scipy import io
from matplotlib import pyplot as plt
class DBSCAN(object):
def __init__(self,x,epsilon,minpts):
# The number of input dataset
self.n = len(x)
# Euclidean distance
p, q = np.meshgrid(np.arange(self.n), np.arange(self.n))
self.dist = np.sqrt(np.sum(((x[p] - x[q])**2),2))
# label as visited points and noise
self.visited = np.full((self.n), False)
self.noise = np.full((self.n),False)
# DBSCAN Parameters
self.epsilon = epsilon
self.minpts = minpts
# Cluseter
self.idx = np.full((self.n),0)
self.C = 0
self.input = x
def run(self):
# Clustering
for i,vector in enumerate(x):
if self.visited[i] == False:
self.visited[i] = True
self.neighbors = self.regionQuery(i)
if len(self.neighbors) > self.minpts:
self.C += 1
self.expandCluster(i)
else : self.noise[i] = True
return self.idx,self.noise
def regionQuery(self, i):
g = self.dist[i,:] < self.epsilon
Neighbors = np.where(g == True)[0].tolist()
return Neighbors
def expandCluster(self, i):
self.idx[i] = self.C
k = 0
while True:
try:
j = self.neighbors[k]
except:pass
if self.visited[j] != True:
self.visited[j] = True
self.neighbors2 = self.regionQuery(j)
if len(self.neighbors2) > self.minpts:
self.neighbors = self.neighbors+self.neighbors2
if self.idx[j] == 0 : self.idx[j] = self.C
k += 1
if len(self.neighbors) < k:
return
def sort(self):
cnum = np.max(self.idx)
self.cluster = []
self.noise = []
for i in range(cnum):
k = np.where(self.idx == (i+1))[0].tolist()
self.cluster.append([self.input[k,:]])
self.noise = self.input[np.where(self.idx == 0)[0].tolist(),:]
return self.cluster, self.noise
def plot(self):
self.sort()
fig, ax = plt.subplots()
for idx,group in enumerate(self.cluster):
ax.plot(group[0][:,0],
group[0][:,1],
marker='o',
linestyle='',
label=idx)
ax.plot(noise[:,0],
noise[:,1],
marker='x',
linestyle='',
label='noise')
ax.legend(fontsize=10, loc='upper left')
plt.title('Scatter Plot of Clustering results', fontsize=15)
plt.xlabel('X', fontsize=14)
plt.ylabel('Y', fontsize=14)
plt.show()Results
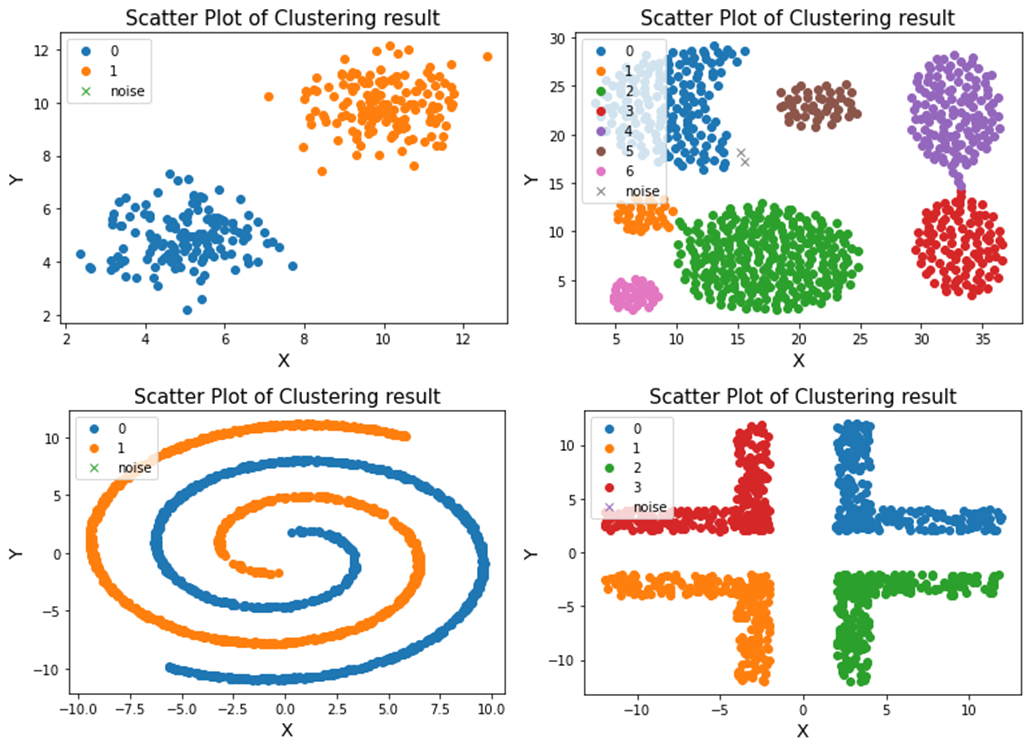
사용된 2차원 공간 데이터 링크
github.com/DEEPI-LAB/clustering-dataset
DEEPI-LAB/clustering-dataset
2d spatial dataset for clustering evaluation. Contribute to DEEPI-LAB/clustering-dataset development by creating an account on GitHub.
github.com
Your Best AI Partner DEEP.I
AI 바우처 공급 기업
객체 추적 및 행동 분석 솔루션 | 제조 생산품 품질 검사 솔루션 | AI 엣지 컴퓨팅 시스템 개발
인공지능 프로젝트 개발 외주 및 상담
E-mail: contact@deep-i.ai
Site: www.deep-i.ai
딥아이 DEEP.I | AI 기반 지능형 기업 솔루션
딥아이는 AI 기술의 정상화라는 목표를 갖고, 최첨단 딥러닝 기술 기반의 기업 솔루션을 제공하고 있으며, 이를 통해 고도의 AI 기반 객체 탐지, 분석, 추적 기능을 통합하여 다양한 산업 분야에
deep-i.ai
'Python > Python' 카테고리의 다른 글
| [Python] Windows에서 파이썬 아나콘다 가상 환경 만들기 (0) | 2021.01.13 |
|---|---|
| [Python] 파이썬 OpenCV를 이용한 성별 및 나이 예측하기 (0) | 2021.01.06 |
| [YOLO] 객체 탐지 알고리즘 학습을 위한 이미지 데이터 라벨링 #3 YOLO 라벨링 프로그램 (2) | 2020.12.02 |
| [Python] 파이썬을 이용한 다층신경망 (Multi-Layer Perceptron: MLP) 구현하기 (XOR 문제) (0) | 2020.11.28 |
| [Python] PyTicToc 파이썬에서 경과 시간 간편하게 측정하기 (0) | 2020.11.25 |